
Google ci porta di fatto nel futuro con una nuova super risoluzione, un livello di qualità delle immagini che non si era mai visto prima: ecco che cosa è riuscita a fare Big G. 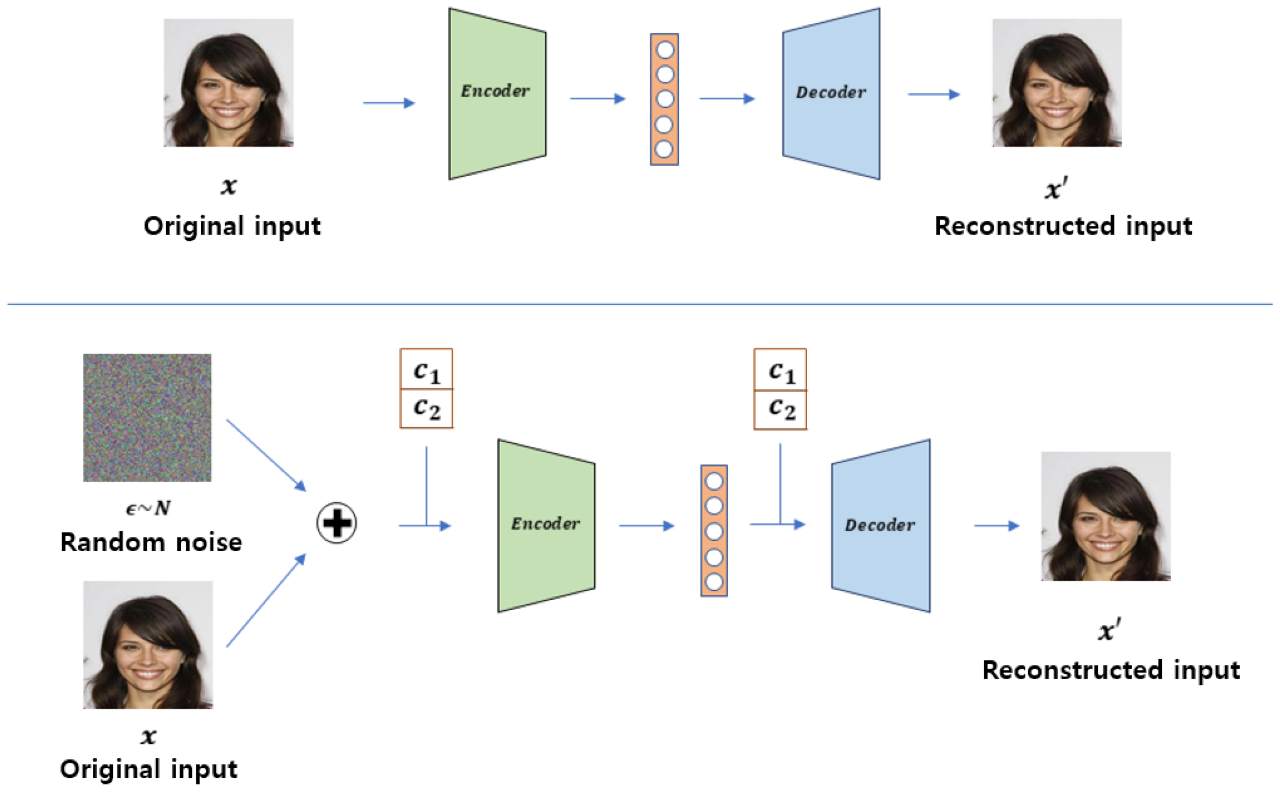
Qualcuno di voi avrà sicuramente notato, in particolare nei film e nelle serie tv più datate, che spesso e volentieri agenti della polizia americani, detective, e federali, riescono ad estrapolare da un’immagine tutta “pixelata”, quindi a bassa risoluzione, trasformandola in un una fotografia perfetta di un dettaglio che può essere ad esempio la targa di un’auto o il viso di una persona. Ovviamente tutto ciò non è possibile perchè il computer non è in grado di aggiungere informazioni ad un file ove questo non li presenta. 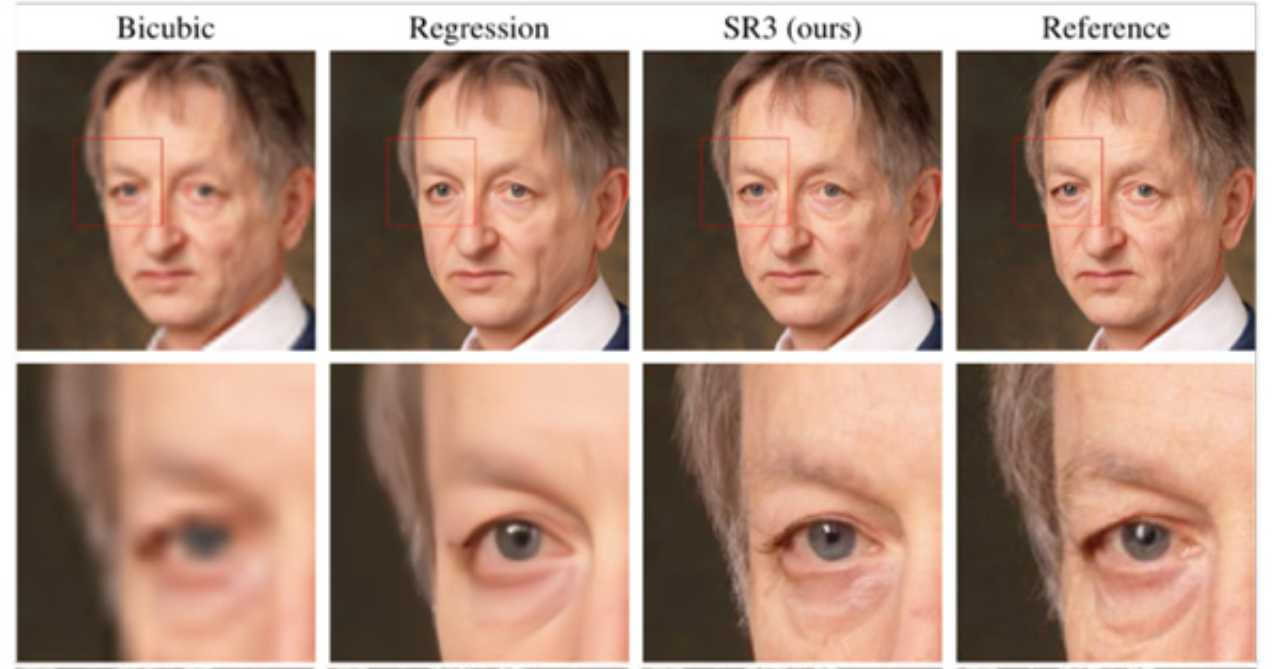
GOOGLE INTRODUCE LA SUPER RISOLUZIONE: COS’ TRASFORMA “MAGICAMENTE” LE IMMAGINI
POTREBBE INTERESSARTI → Google e Microsoft si uniscono per la Cyber-sicurezza degli USA: varati ben 30 miliardi di dollari
Ma attenzione perchè Google è riuscita ad avvicinarsi moltissimo a tale magia, facendo molto meglio rispetto agli attuali programmi di elaborazione di foto che permettono di aumentare già la risoluzione degli scatti senza che la sua qualità ne risulti compromessa. Si tratta di una vera e propria super risoluzione quella del gigante della tech degli Stati Uniti, e che apre a scenari fino ad oggi inimmaginabili e a numerosi campi di applicazione. Per riuscire a dare vita a questa “diavoleria”, come si descriverebbe nei tempi andati, Google ha messo in campo non una ma ben due tecnologie di AI, intelligenza artificiale, in grado appunto di trasformare una immagine in bassa risoluzione in una ad alta attraverso una tecnica di distruzione e ricostruzione selettiva. La prima componente che va ad agire sull’immagine è la SR3, la Super-Resolution via Repeated Refinements, una sorta di software che permette di ricostruire un’immagine a bassa risoluzione partendo dal “rumore puro”.
POTREBBE INTERESSARTI → Svolta in Google Maps: presto verrà rilasciata una funzione salva-portafogli davvero utile
Attraverso l’SR3 vengono “corrotti” i dati di addestramento aggiungendo poi in maniera progressiva del rumore gaussiano, cancellando lentamente tutti i dettagli fino a che lo scatto non diventa solo rumore puro. A questo punto si addestra una rete neurale che inverte il processo di corruzione che va a sintetizzare i dati del rumore puro, eliminandolo a poco a poco fino a che non si crea un campione privo di rumore. E’ qui che entra in gioco il Cascaded Diffusion Models (CDM), il secondo componente AI, che applica il rumore gaussiano in maniera intelligente e la sfocatura dell’immagine di output, riprendendo poi il processo. Questa tecnica si chiama “conditioning augmentation” e permette quindi di migliorare la qualità dell’immagine ad un livello superiore rispetto ai metodi di upscaling al momento in circolazione, come ad esempio gli spesso citati BigGAN-Deep e VQ-VAE-2.





